
保育園の連絡帳が電子化される中、便利になってとても嬉しい反面、なんか寂しい、データをキレイに残したい、と思いませんか?
せっかくの我が子の成長記録、たとえ忙しくて見返すことはないかもしれないとはいえ、退園したら見られない、pdfでダウンロードできても見にくい、などの問題を解決するため、JavascriptのNode.js製のライブラリ、puppeteerとNotionのAPIを使って、テキストデータを収集する時短ツールを作りました。ツールを動かすために、有料のサービスはなし、全て無料でできます。
プログラマーのパパママで、こんなこと、考える人はいるのだろうか。。。プログラミング初心者の1歳児ママでもがんばってつくれました。どなたかの参考になれば嬉しいです😊
Puppeteerとは?
Puppeteerは、Node.js上で動作するGoogleのライブラリで、ブラウザ自動化ツールとして使用されます。操り人形、パペット(puppet)のように、人がブラウザ上でクリックするなどして行っている動作を自動で実行します。
保育園の連絡帳アプリがChromeで動くことが前提
保育園側の連絡帳WebアプリがAPI公開している、なんてことはなさそうなので、自分で操作することにしました。パスワードでログインなどするため、操り人形のようにダイレクトに操作してくれるpuppeteerは相性がいいです。
Puppeteerは、Google ChromeとChromiumブラウザをサポートしているので、データ入手先のページがGoogle Chromeで動かなければ、使えません。
また、連絡帳アプリは、園関係者のみが使う前提のため、一度に大量のアクセスを受け入れる仕様になっていないと思われることから、開発したからといって、むやみやたらとツールを使って、データを1日に何度も取るのはやめましょう。
puppeteerのメリットとデメリット
以下は、Puppeteerのメリットとデメリットです。
メリット:
- ブラウザ上の操作やページのスクレイピングが容易にできる。
- オフスクリーンレンダリング機能を提供するため、ヘッドレスブラウザを使用したスクレイピングも可能。
- テスト自動化に役立つ機能を多数提供している。
- Chrome DevTools Protocolを介してブラウザと通信するため、高度な操作が可能。
- シンプルで使いやすい。
- 並列処理が可能なため、複数のタブやページを同時に操作できます。
デメリット:
- Puppeteerは、Node.jsでのみ動作するため、JavaScriptを書く必要があります。
- ブラウザ自動化に関する知識が必要であるため、学習コストがかかる場合があります。
- ブラウザの仕様変更に追従する必要があるため、アップデートが頻繁に行われます。
- ブラウザの仕様変更によって、以前動作していたコードが動作しなくなる場合があります。
どのツールでも言えることですが、随時、最新情報の確認が必要ですね。
個人的には、シンプルで使いやすい、というのは一番のメリットだと思います。
作業環境の用意とPuppeteerのインストール
作業環境を用意しましょう。
ちなみに、以下のスペックで作業しています。
- PC: Macbook Air
- コードエディタ:Visual Studio Code(VScode)
作業フォルダを作成し、Terminalで作業フォルドに移動したあと、 puppeteerをインストールします。
$ cd 作業フォルダ $ npm install puppeteer
メインのJavascriptファイルを作成します。これは、データ取得&notionへ送信するために使います。
VScodeで作業フォルダオープンして、New Fileで、getDiary.js、として作ります。データの名前はなんでもいいので、必要に応じて、好きな名前にしてください。
puppeteerを使うため、コードの初めに、以下入れておきます。
const puppeteer = require('puppeteer');
getDiary.jsと同じフォルダ内に、getDiary.jsで得たデータをnotionに受け取ってもらうためのJavascriptファイルを、post_to_notion.js、として作ります。
notionに接続するため、コードの初めに、以下入れておきます。
require('dotenv').config()
const { Client } = require('@notionhq/client');
const notion = new Client({ auth: process.env.NOTION_API_KEY });
notionのAPI keyは大事な情報なので、.envでJavascriptファイル本体には書かなくていいようにしています。
同フォルダのトップレベルに.envファイルを作成して、以下のように、大事な情報は分けて書いておきましょう。
NOTION_API_KEY=「notionからコピーする」 NOTION_DATABASE_ID=「notionからコピーする」
データ取得・送信コード作成 – getDiary.js
基本情報の定義
まずは、パスワードや基本情報を定義していきます。
const LOGIN_URL = 'データを取るサイトのログインページのURL'; const LOGIN_USER = 'データを取るサイトのユーザーネーム'; const LOGIN_PASS = 'データを取るサイトのパスワード'; const TARGET_URL = '目的のデータがあるページのURL'; const LOGIN_USER_SELECTOR = 'input[id=userId]'; const LOGIN_PASS_SELECTOR = 'input[type=password]'; const LOGIN_SUBMIT_SELECTOR = 'button[type=submit]'; // 前日分のデータを得たいとき const PREVIOUS_SELECTOR = 'button[id=previousDay]';
LOGIN_URL、LOGIN_USER、LOGIN_PASS、TARGET_URLの情報を入力する。
****_SELECTORはそれぞれ、ユーザーネームや、パスワード、送信ボタン、前日へ移動するボタンの入力欄を特定するCSSセレクタです。‘input[id=userId]’などは、一例ですので、ChromeのDev Toolで一つ一つ確認して、入れていきます。
取得するデータを決める
連絡帳から、取りたいデータを決め、それぞれ、定義します。
ここでは、以下のように名前をつけました。
- diary1:保育園から保護者への連絡メモ
- diary2:保護者から保育園への連絡メモ
- diary_date:日付
登園時の体温とか、爪切ったとか、食事内容などの細かいデータは、見返してもつまらなさそうな(食事については、ズボラがバレる)ため、抽出しないこととしています。
もちろん、必要や好みに合わせて、取得データを増やすことができます。
ページにログインして、目的のデータのあるページに行く
Puppeteerでブラウザを開き、新規ページをつくってもらい、ログインしてから、目的のデータがあるページに行くようコードを書きます。
(async (diary1, diary2, diary_date) => {
const browser = await puppeteer.launch({ // ブラウザを開く
headless: false, // ブラウザを表示するか (デバッグの時は false )
});
const page = await browser.newPage(); // 新規ページを開く
// ログイン画面でログイン
await page.goto(LOGIN_URL, { waitUntil: 'domcontentloaded' });
await page.type(LOGIN_USER_SELECTOR, LOGIN_USER); // ユーザー名を入力している
await page.type(LOGIN_PASS_SELECTOR, LOGIN_PASS); // パスワードを入力している
await Promise.all([
page.waitForNavigation({ waitUntil: 'networkidle2' }),
page.click(LOGIN_SUBMIT_SELECTOR),
]);
await page.goto(TARGET_URL);
これで、pupeteerでブラウザを開いて、保育園のページにログインし、目的のページに行くことができました。
初めの1行は、Notionに送るためのものです。
目的のデータを特定する
次に、日付と連絡メモのデータを特定します。
var diary_date = await page.evaluate(() => {
return document.querySelectorAll('[nameなど特定できるもの]')[0].innerText;
});
var diary1 = await page.evaluate(() => {
return document.querySelectorAll('[nameなど特定できるもの]')[0].defaultValue;
});
var diary2 = await page.evaluate(() => {
return document.querySelectorAll('[nameなど特定できるもの]')[0].defaultValue;
});
querySelectorAllでは、Chromeのdev toolで、取りたいデータの場所を特定するキーワードを拾って来る必要があります。私の場合は、[name=”nrsryCondition”]を拾ってきて、保育園からの連絡メモの場所を特定しました。日付については、nameで特定できず、classの名前を使うことになったので、nameができなかった場合は、いろいろ試してみましょう。
データを送って、ブラウザを閉じる
最後に、notionにデータを送って、ブラウザを閉じて終了です。
await postToNotion(diary1, diary2, diary_date)
await browser.close();
})();
データの一番上(const puppeteer = require(‘puppeteer’);の次の行)にも、notionに送る用のコードを定義しておきましょう。
const { postToNotion } = require('./post_to_notion')
その他、必要に応じて使うコード
その他、Terminalでログが見たければ、ブラウザを閉じる前に、console.logを入れておいても良いでしょう。
console.log(diary_date, 'date_date')
console.log(diary1, 'diary1')
console.log(diary2, 'diary2')
また、デフォルトでは当日の記録にしか飛べなかったため、前日のデータを得るために、前日分、にアクセスするためのコードを加えました。
await page.click(PREVIOUS_SELECTOR)
await page.waitForNavigation({ waitUntil: 'networkidle2' })
このコードは、必要に応じて、command+/ でオン・オフしながら使っています。
notionにデータを受け取ってもらうコードを作成 – post_to_notion.js
トップに書いた、
require('dotenv').config()
const { Client } = require('@notionhq/client');
const notion = new Client({ auth: process.env.NOTION_API_KEY });
このコードの続きを書いていきます。
notionのデータベースの作り方や、APIの取り方は、公式や他サイトを参考にしてください。ここでは、notionでデータベース用意済み、API keyも取得済みとして、進めます。
notionのdevelopper toolで、サンプルコードを確認
notionのdevelopper toolで、API Referenceのサンプルコードがあったので、これを適応して作ります。以下、サンプル。
(async () => {
const databaseId = 'd9824bdc-8445-4327-be8b-5b47500af6ce';
const response = await notion.databases.query({
database_id: databaseId,
filter: {
or: [
{
property: 'In stock',
checkbox: {
equals: true,
},
},
{
property: 'Cost of next trip',
number: {
greater_than_or_equal_to: 2,
},
},
],
},
sorts: [
{
property: 'Last ordered',
direction: 'ascending',
},
],
});
console.log(response);
})();
これを適応して、こうなりました。database idは、constで定義しなくてもできました。
const postToNotion = async (diary1, diary2, diary_date) => {
const response = await notion.pages.create({
"parent": {
"type": "database_id",
"database_id": "notionからコピペ"
},
"properties": {
"date": {
"rich_text": [
{
"text": {
"content": diary_date
}
}
]
},
"nursery_condition": {
"rich_text": [
{
"text": {
"content": diary1
}
}
]
},
"message": {
"rich_text": [
{
"text": {
"content": diary2
}
}
]
},
}
});
console.log(response);
}
create以下の文字列は、一度、notionのデータベースから構成を読み取り、加工しています。
notionデータベースの構成を読み取る
構成を読み取りについて、は以下のとおりです。
作成するデータベースに応じて、内容が変わってくるので、新しくget_notion_data.jsなどの名前で、新しいファイルを作り、自分の作ったデータベースの構成を確認します。
require('dotenv').config();
const { Client } = require('@notionhq/client');
const notion = new Client({ auth: process.env.NOTION_API_KEY });
(async () => {
const databaseId = 'notionからコピペ';
const response = await notion.databases.query({
database_id: databaseId,
sorts: [
{
property: 'id',
direction: 'descending',
},
],
});
console.log(JSON.stringify(response, null, 2))
})();
get_notion_data.jsを実行して得た情報をもとに、post_to_notion.jsのcreate以下のデータを更新しました。
モジュールをエクスポートする
post_to_notion.jsの最後に、このモジュールをエクスポートして、getDiary.jsで使えるようにします。
module.exports = { postToNotion }
以上で、ボタンひとつで、データを取得してnotionのデータベースにとっておいてくれるようになります。notion databaseのスクショを貼り付けておきます。idとタイトルは、ブログ化するときに作りやすくするため、追加しました。
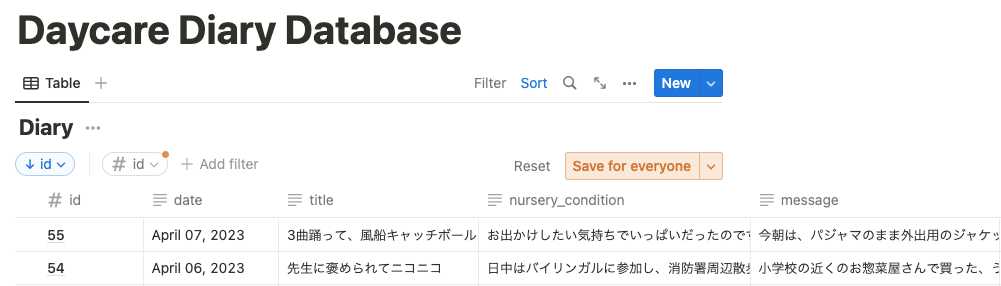
ボタンひとつでnotion databaseにテキストデータを保存
getDiary.jsを実行(Run)するだけで、必要なテキストデータがnotionに保存できるようになりました。やったね!
Databaseのままでは読みにくいので、Next.jsで自動でブログにしてくれるようコードも書きました。
Next.jsのチュートリアルを少しいじったくらいですが、↓こんな感じに仕上がりました。

notion databaseを使ってNext.jsでブログ化にするやり方については、機会があれば、今後、記事にしようと思います。


コメント